Kryptografische Hash-Funktionen bilden das Rückgrat von Kryptoverfahren und -algorithmen [MvV92].
Wie die aus der Informatik bekannten Hash-Funktionen auch, bilden sie eine große Eingangsmenge
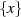 eindeutig (deterministisch) auf eine viel kleinere Ausgangsmenge
eindeutig (deterministisch) auf eine viel kleinere Ausgangsmenge 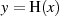 ab. Sie haben jedoch
folgende ergänzende Eigenschaften, welche deren algorithmische Komplexität mit dem jeweiligen
Stand der Technik in Verbindung bringen:
ab. Sie haben jedoch
folgende ergänzende Eigenschaften, welche deren algorithmische Komplexität mit dem jeweiligen
Stand der Technik in Verbindung bringen:
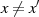 zu finden (wahlfrei), die denselben
Hashwert
zu finden (wahlfrei), die denselben
Hashwert 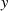 besitzen (Kollisionsfreiheit).
besitzen (Kollisionsfreiheit).
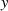 kann
man praktisch keinen zugehörigen Wert
kann
man praktisch keinen zugehörigen Wert 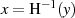 berechnen (1. Urbild-Festigkeit).14
berechnen (1. Urbild-Festigkeit).14
 einen weiteren Wert
einen weiteren Wert
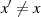 zu finden, der denselben Hash-Wert
zu finden, der denselben Hash-Wert 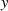 erzeugt (2. Urbild-Festigkeit).
erzeugt (2. Urbild-Festigkeit).Insbesondere ältere Hash-Funktionen, wie z. B. der MD5 können dies heute nicht mehr gewährleisten, aber auch der SHA-1 gilt seit 2005 als „geknackt”. Alternativen wie SHA-256 oder SHA-512 (auch kurz SHA-2 genannt) stehen zwar zur Verfügung, werden aber noch nicht überall konsequent genutzt.15
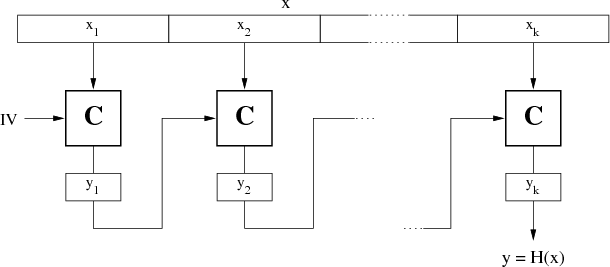
Wirkprinzip
Die Berechnung des Hash-Wertes 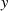 erfolgt üblicherweise durch Zerlegung des Eingangs-Vektors
erfolgt üblicherweise durch Zerlegung des Eingangs-Vektors  in
in
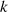 Blöcke fester Breite, die dann iterativ mit Hilfe einer nichtlinearen Kompressionsfunktion
Blöcke fester Breite, die dann iterativ mit Hilfe einer nichtlinearen Kompressionsfunktion 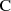 verarbeitet
werden. Abbildung 2.1 zeigt die unter dem Namen Merkle/Damgård-Konstruktion bekannte
Struktur [Mer90, Dam90].16
Für jeden Zwischenwert gilt ausgehend von
verarbeitet
werden. Abbildung 2.1 zeigt die unter dem Namen Merkle/Damgård-Konstruktion bekannte
Struktur [Mer90, Dam90].16
Für jeden Zwischenwert gilt ausgehend von 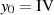 die Gleichung
die Gleichung 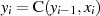 und so für das
Ergebnis:
und so für das
Ergebnis: 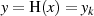 .
.